Better AI for Everyone
Building trusted, safe, and efficient AI requires better systems for measurement and accountability. MLCommons’ collective engineering with industry and academia continually measures and improves the accuracy, safety, speed, and efficiency of AI technologies.

125+
MLCommons Members and Affiliates
6
Benchmark Suites
55,000+
MLPerf Performance Results to-date
Accelerating Artificial Intelligence Innovation
In collaboration with our 125+ founding members and affiliates, including startups, leading companies, academics, and non-profits from around the globe, we democratize AI through open industry-standard benchmarks that measure quality and performance and by building open, large-scale, and diverse datasets to improve AI models.
Focus Areas
We help to advance new technologies by democratizing AI adoption through the creation and management of open useful measures of quality and performance, large scale open data sets, and ongoing research efforts.

Benchmarking
Benchmarks help balance the benefits and risks of AI through quantitative tools that guide effective and responsible AI development. They provide consistent measurements of accuracy, safety, speed, and efficiency which enable engineers to design reliable products and services and help researchers gain new insights to drive the solutions of tomorrow.
Datasets
Evaluating AI systems depends on rigorous, standardized test datasets. MLCommons builds open, large-scale, and diverse datasets and a rich ecosystem of techniques and tools for AI data, helping the broader community deliver more accurate and safer AI systems.

Research
Open collaboration and support with the research community helps accelerate and democratize scientific discovery. MLCommons shared research infrastructure for benchmarking, rich datasets and diverse community, help enable the scientific research community to derive new insights for new breakthroughs in AI, for the betterment of society.
Members
MLCommons is supported by our 125+ founding members and affiliates, including startups, leading companies, academics, and non-profits from around the globe.
Founding Members




























Members
























Join Our Community
MLCommons is a community-driven and community-funded effort. We welcome all corporations, academic researchers, nonprofits, government organizations, and individuals on a non-discriminatory basis. Join us!

Featured Articles
MLPerf Tiny v1.2 Results
MLPerf Tiny results demonstrate an increased industry adoption of AI through software support

Announcing MLCommons AI Safety v0.5 Proof of Concept
Achieving a major milestone towards standard benchmarks for evaluating AI Safety

The AI Safety Ecosystem Needs Standard Benchmarks
IEEE Spectrum contributed blog excerpt, authored by the MLCommons AI Safety working group

New MLPerf Inference Benchmark Results Highlight The Rapid Growth of Generative AI Models
With 70 billion parameters, Llama 2 70B is the largest model added to the MLPerf Inference benchmark suite.

Llama 2 70B: An MLPerf Inference Benchmark for Large Language Models
MLPerf Inference task force shares insights on the selection of Llama 2 for the latest MLPerf Inference benchmark round.

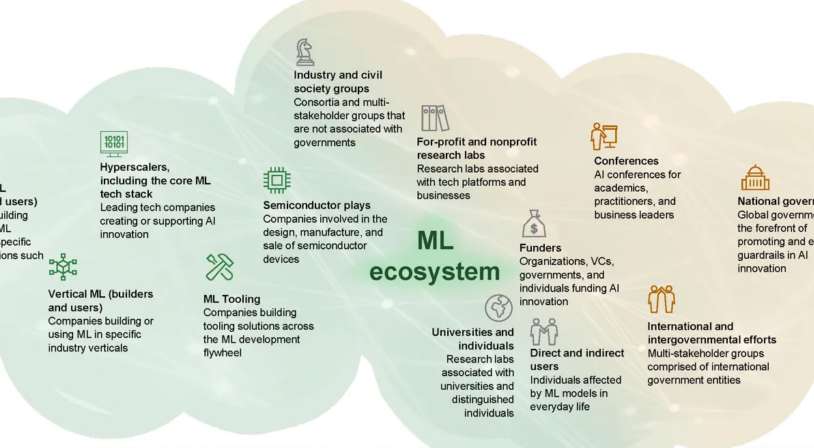
Perspective: Unlocking ML requires an ecosystem approach
Factories need good roads to deliver value